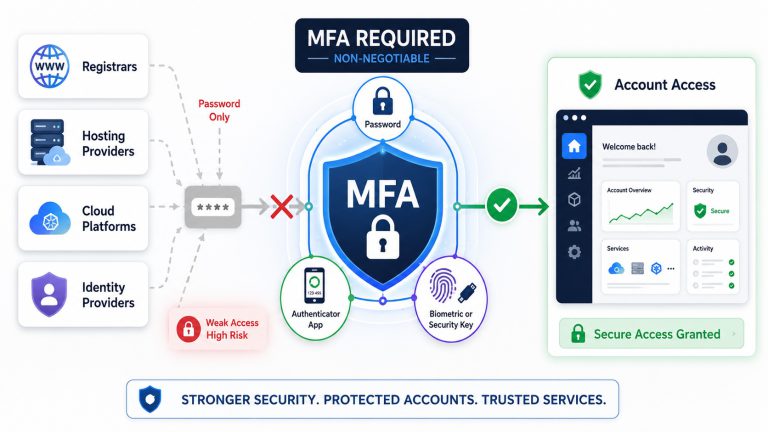
“Question 2” – Into AI, asking the right questions: How to Spot Email Scams
This is the second in a series demonstrating how AI can help us investigate the systems shaping our world. The first looked outward, at ecosystems and economics, and who pays when natural systems fail. This one looks at something closer to home, that lands in your inbox every day, and asks why we are still…